From PDFs to Usable Data
for the International Journalism Festival 2012
Dan Nguyen twitter: @dancow / @propublica
April 26, 2012
Shortlink: http://bit.ly/pdftodata
for the International Journalism Festival 2012
Dan Nguyen twitter: @dancow / @propublica
April 26, 2012
Shortlink: http://bit.ly/pdftodata
Note: This guide only covers the better known, more useful methods. There are dozens of programs and websites you'll find if you do a Google search for "convert PDF to Excel"
But the focus of the guide is on the general strategies and insight about data so that you can make the best decision for your own situation.
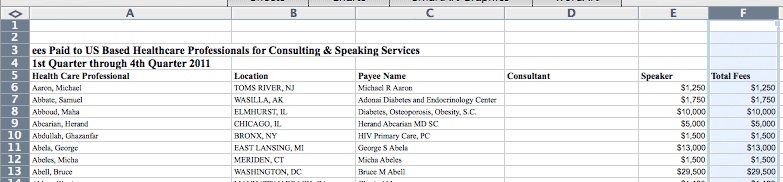
Adobe's ubiquitous format. Great for sending around to someone's printer.

But without additional work on your part, a table of data inside a PDF is just as inert as if it were on printed paper.
You can't sort, sum, or sift through it.
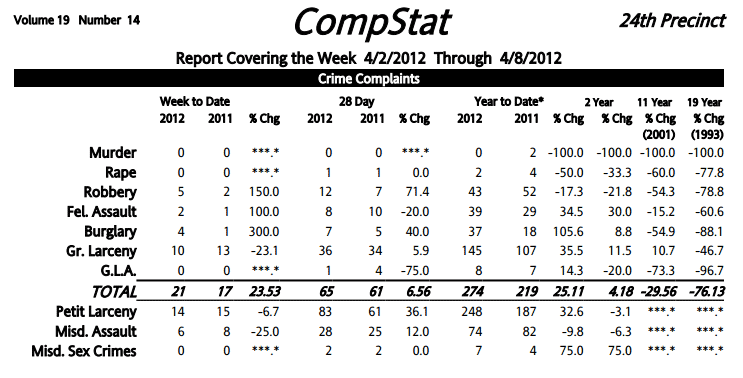
Before the widespread use of the Web, we filled out paper forms and our databases generated paper printouts.
There's a lot of software to move those "papers" online in PDF format.

Thus, there's lots of data locked up in the PDF format. Most of it isn't hard to get at, if you know some basic tools and strategies.
We'll examine some basic techniques and tools to convert PDF data from this [link to original file] [local version]:
They each require fundamentally different approaches; image-PDFs are much harder to work with.

These are created by software that convert text-based formats – such as Microsoft Word documents and spreadsheets – into Adobe's format.
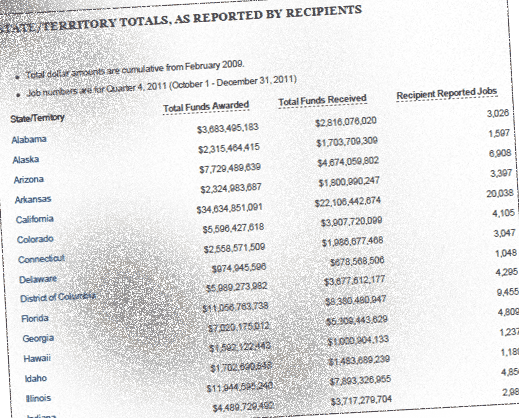
These typically are scanned documents – i.e. photos of documents. To humans, it may look like it contains real text. But it's just a photo to the computer.
Examples: 1
|
Lines and words can be highlighted (link)  |
Nothing to highlight (link)  |
Getting actual text-data from image-based PDFs requires all the work of extracting from text-PDFs, plus an extra set of tools to use beforehand. We'll cover this process later.
The natural thing to try (example pdf).


Pros:
Cons:
Note: In Adobe Acrobat, you can highlight text and select an option to convert to table. However, Acrobat costs money and the feature can be inconsistent.
Sometimes the PDF is built with structured XML or HTML. Acrobat and other programs can successfully extract and preserve this structure. But you might need to do some programming to extract it (check out Nokogiri for Ruby and Beautiful Soup for Python).
Pros:
Cons:
Several cloud-based services allow you to upload a PDF. The service processes it and sends you a link to the spreadsheet file by email.
Example services include Cometdocs.com and Zamzar.com Most of these services are free with a "pro" option.
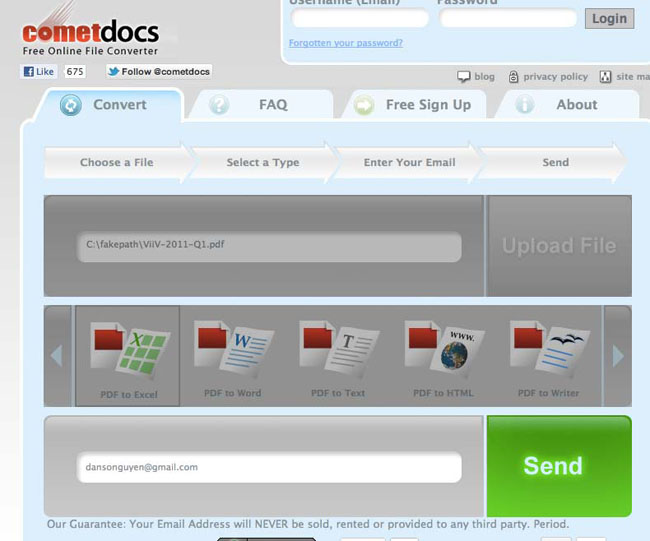
The service sends you an email with download link after a few minutes (sometimes longer).
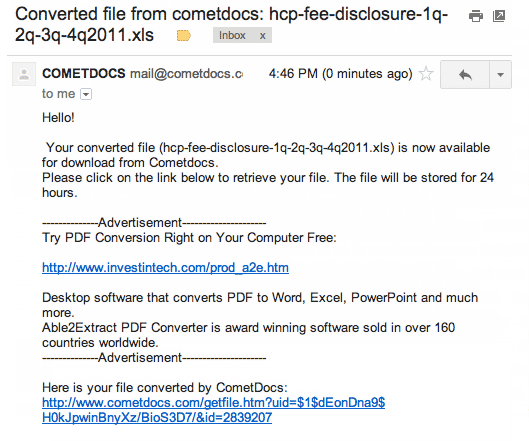
Pros:
Cons:
When every digit and character is critical, you may have to do a little manual work.
pdftotext is part of the free Xpdf toolkit
You run it from the command-line with the -layout option:

And you essentially get the text as-is (PDF / output text):

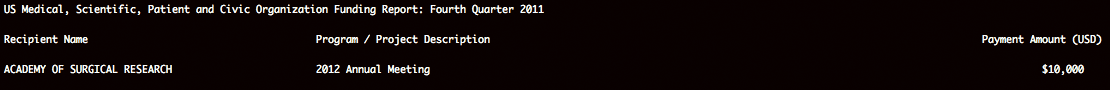
So how do you get the raw text output from pdftotext into Excel?
Spreadsheets essentially consist of raw text with some kind of common character – a delimiter – that separates each column.
Common delimiters include:
The raw text created by pdftotext isn't delimited because of the varying number of spaces between each column
(link to text).

You can either:
You can easily see that each column is separated by at least two or more spaces.
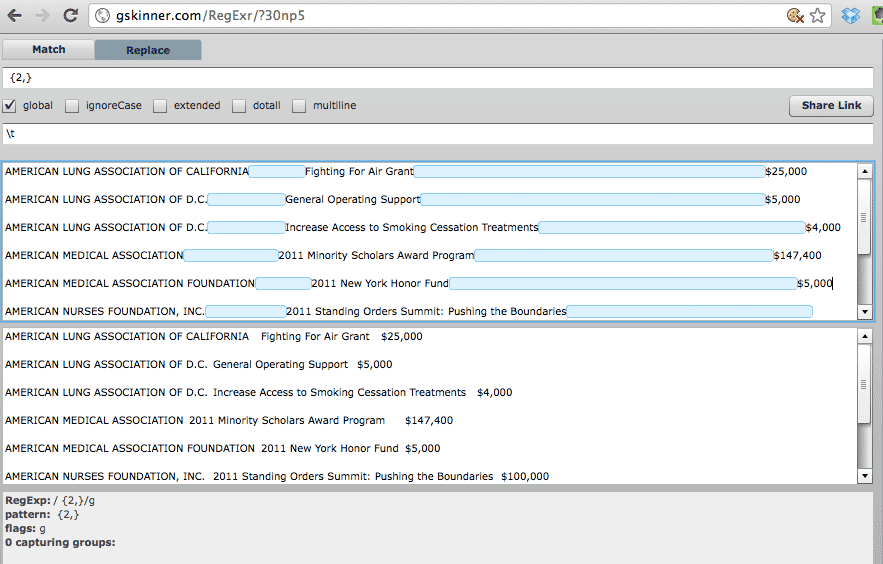
The regular expression pattern to find:
{2,}
...there's a space before the {
Replace with the delimiter of your choice. Here's a tab:
\t
The result: delimited text file
Regular expressions are like find-and-replace in your text-editor:

Free text-editors that can do this: TextWrangler for Mac, Notepad++ for Windows
Try it out interactively: http://regexr.com?30np5
[interactive link] / delimited text file
When a PDF is composed of images, the text you might see is not seen by the computer as actual text. Programs such as pdftotext will not work because there is no text to extract.
Therefore, an image-PDF of data tables won't contain data. Just as this cat photo doesn't actually contain the word, "cat":

Computers can be trained to recognize faces. They can also be trained to recognize lettering:
| Easy | Hard |
|---|---|

Example of Face.com's face-detection API
|

Photo from White House Flickr
|
Its accuracy depends on the quality of the image and the program's training.
| Easy | Hard |
|---|---|
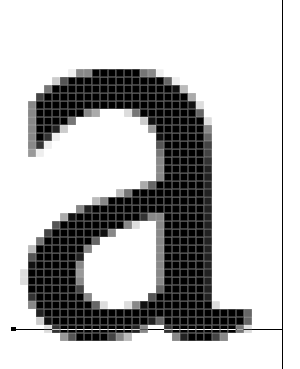 |
 |
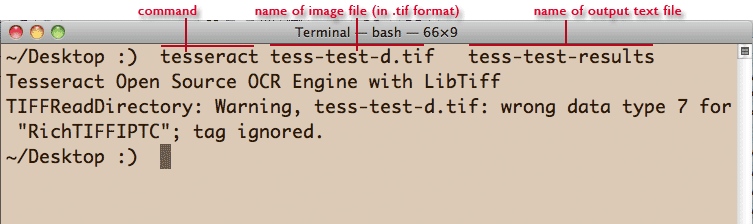
This is a free, command-line OCR program maintained by Google. It works well out-of-the-box and – with some work – can be trained for specific character sets.

Pros:
Cons:
This commercial program has OCR built-into-it.

Pros:
Cons:
Google Docs can perform OCR on uploaded images and PDFs
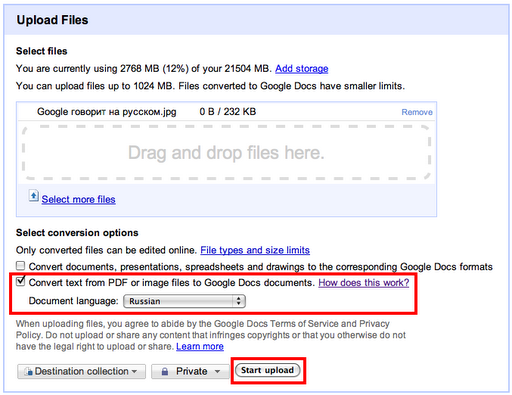
Pros:
Cons:
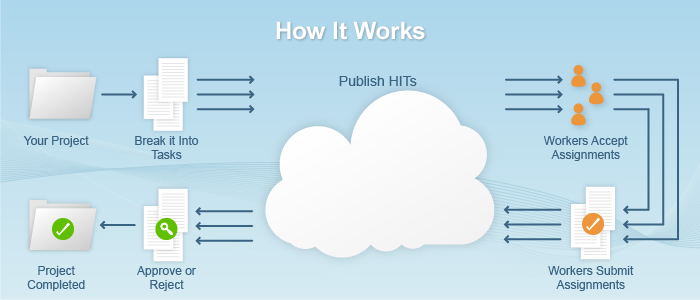
Have hundreds, thousands of humans to transcribe your images. Amazon provides a way for you to send micro-tasks (e.g. "Type out the text in the third row of this table") to users looking for easy, quick jobs.
Pros:
Cons:
Every tool covered so far works mostly as-is, no programming required.
If you know some programming, it can be helpful to "glue" together a bunch of repetitive tasks.
Examples:
Though New York City is famed for its use of statistics in fighting crime, the department publishes very little data on its website.
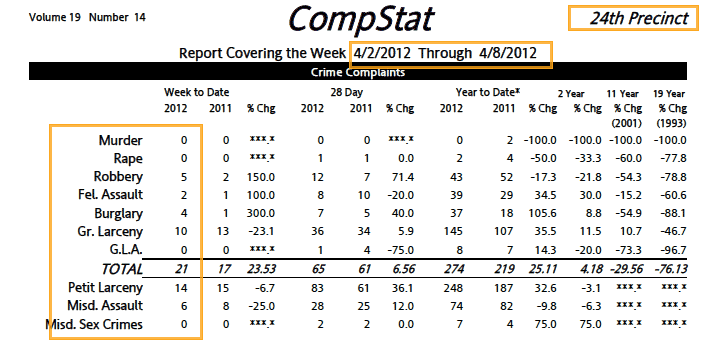
Doing this by hand – downloading every PDF file and entering even just the few numbers each contains, every single week – is prone to error and brain atrophy.
A programming script can automate every step, turning these PDFs into data in just a minute. ScraperWiki has a working example
Download each PDF link on the NYPD stats homepage using simple web scraping (Nokogiri for Ruby, Beautiful Soup for Python)
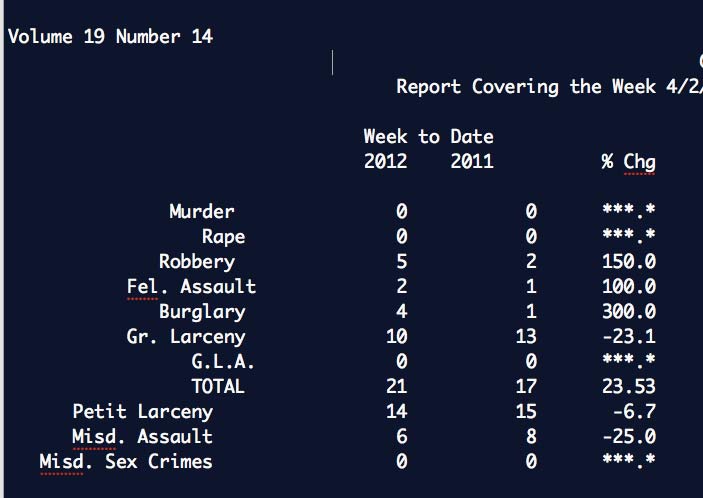
Convert PDF to text. Using pdftotext is an option.
Sample PDF report / text output
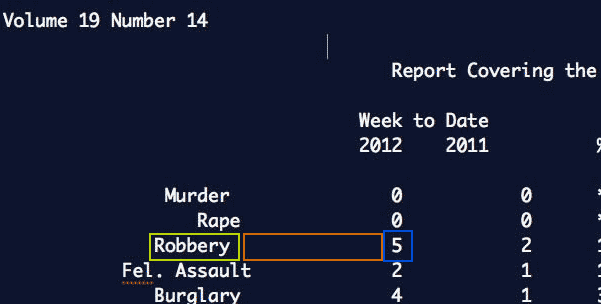
Use text-matching (regular expressions) to capture data points. (interactive link)
Example: Robbery\s{2,}\d+
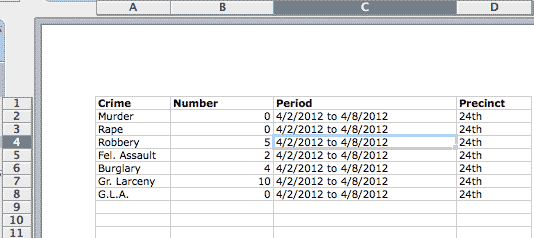
Save as spreadsheet (comma/tab-delimited) format.
Now we can sort/search and look at statistics over time.
Again, check out ScraperWiki's recipe for the NYPD data.
Data is sometimes found only in PDF format.
for the International Journalism Festival 2012
Dan Nguyen twitter: @dancow / @propublica
April 26, 2012
Shortlink: http://bit.ly/pdftodata
Slide format courtesy of Google's html5slides